
Speech and Language Technology for Information Access and Processing Investigators
Jerry Hobbs (PI),
Andreas Stolcke (co-PI)
Project Summary The goal of this DARPA-funded project is to enhance and integrate current speech and natural language processing technology to enable information extraction from audio sources. This effort is a collaboration of SRI's Speech Technology and Research Laboratory and the Natural Language Program in the Artificial Intelligence Center (AIC). In collaboration with AIC's Perception Program we are also working on the integration of vision-based technologies (such as optical character recognition) with speech and natural language. That effort is also known as SIEVE (Speech and Information Extraction for Video Exploitation). In the Press Research Efforts We are presently focusing on a number of fundamental research problems which have to be solved to enable the overall goal of automatically extracting content from audio/video sources. Most of these research efforts are being undertaken in collaboration with other ongoing projects in the STAR Lab and the AI Center. Most of these technologies are being developed in the DARPA Broadcast News domain, with the eventual goal of a sophisticated ``News-on-Demand'' system.
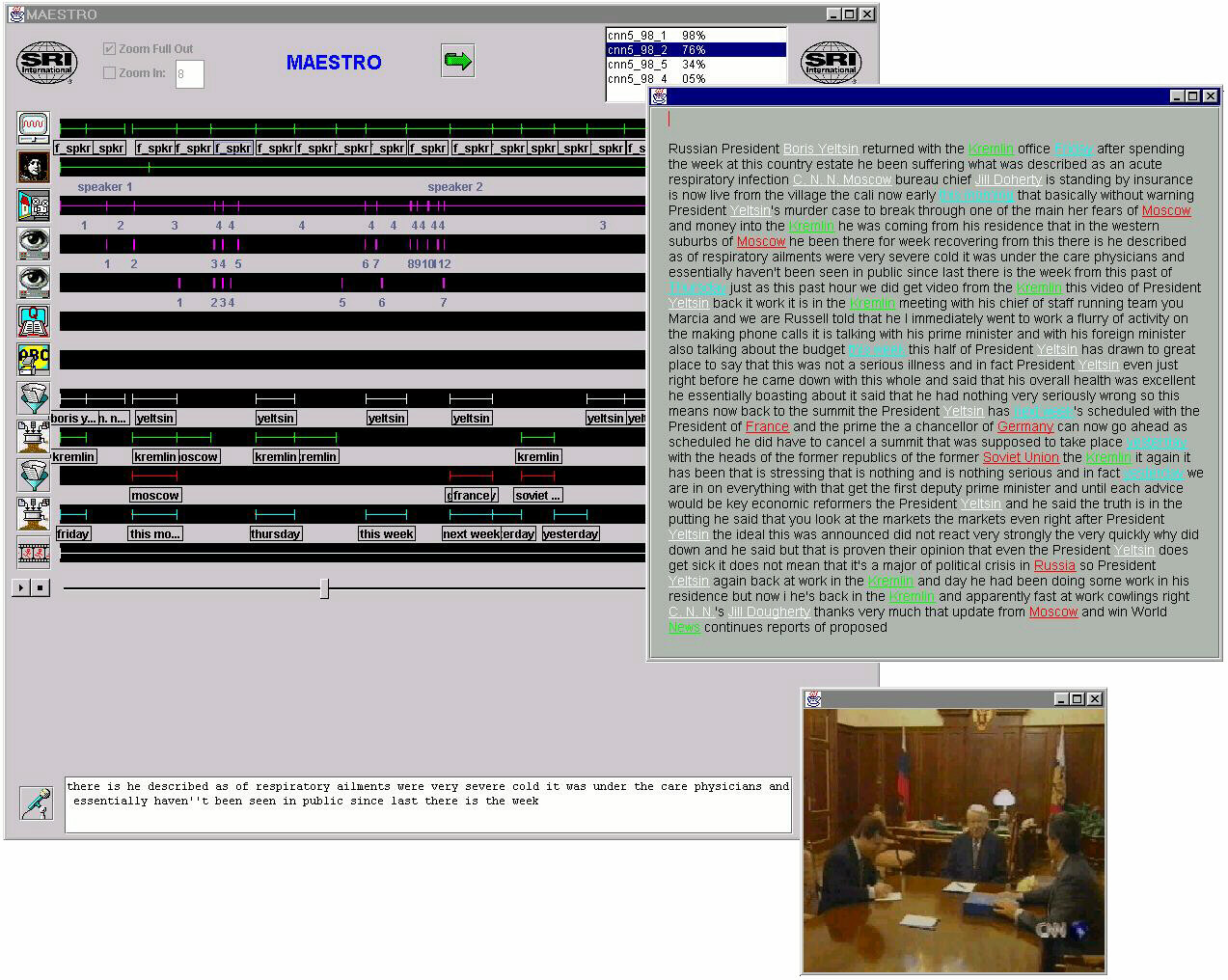
A key focus of the SIEVE project is the integration of many, multi-modal information sources (both auditory and visual) for information extraction purposes. In order to simultaneously browse and visualize a multitude of parallel, time-aligned information sources we developed MAESTRO, a graphical interface for Multimedia Annotation and Enhancement via a Synergy of automatic Technologies and Reviewing Operators. The name is motivated by the appearance of its user interface, which resembles a conductor's score in displaying the results of the various "voices" such as speech recognition, name extraction, scene detection, speaker tracking, topic tracking, etc. A block diagram identifies the various components that provide input to the MAESTRO interface. Funding Information This project is funded through DARPA's Information Technology Office, Allen Sears, Program Manager, under contract N66001-97-C-8544. Publications and Presentations L.P. Heck & A. Sankar (1997), Acoustic Clustering and Adaptation for Robust Speech Recognition, Proc. EUROSPEECH, vol. 4, pp. 1867-1870, Rhodes, Greece. (PDF) A. Stolcke, E. Shriberg, R. Bates, M. Ostendorf, D. Hakkani, M. Plauche, G. Tur, & Y. Lu (1998), Automatic Detection of Sentence Boundaries and Disfluencies based on Recognized Words. Proc. Intl. Conf. on Spoken Language Processing, vol. 5, pp. 2247-2250, Sydney, Australia. (PDF) Multimodal Technology Integration for News-on-Demand. Presentation for DARPA News-on-Demand Compare-and-Contrast Meeting, September, 1998. (PowerPoint source) Combining Words and Prosody for Information Extraction from Speech. Presentation at the DARPA Broadcast News Workshop, Herndon, VA, March 1999. A. Stolcke, E. Shriberg, D. Hakkani-Tur, G. Tur, Z. Rivlin, & K. Sonmez (1999), Combining Words and Speech Prosody for Automatic Topic Segmentation. Proc. DARPA Broadcast News Workshop, pp. 61-64, Herndon, VA. (HTML, PDF) D. Appelt & D. Martin (1999), Named Entity Recognition in Speech: Approach and Results Using the TextPro System. Proc. DARPA Broadcast News Workshop, pp. 51-54, Herndon, VA. (PDF, HTML) D. Hakkani-Tur, G. Tur, A. Stolcke, & E. Shriberg (1999), Combining Words and Prosody for Information Extraction from Speech. Proc. EUROSPEECH, vol. 5, pp. 1991-1994, Budapest. (PDF) A. Stolcke, E. Shriberg, D. Hakkani-Tur, & G. Tur (1999), Modeling the Prosody of Hidden Events for Improved Word Recognition. Proc. EUROSPEECH, vol. 1, pp. 307-310, Budapest. (PDF) Z. Rivlin, D. Appelt, R. Bolles, A. Cheyer, D. Hakkani-Tur, D. Israel, L. Julia, D. Martin, G. Myers, K. Nitz, B. Sabata, A. Sankar, E. Shriberg, K. Sonmez, A. Stolcke, & G. Tur (2000), MAESTRO: Conductor of Multimedia Analysis Technologies, Communications of the ACM 43(2), 57-63, Special Issue on News on Demand, February 2000. (DOI) E. Shriberg, A. Stolcke, D. Hakkani-Tur, & G. Tur (2000), Prosody-Based Automatic Segmentation of Speech into Sentences and Topics, Speech Communication 32(1-2), 127-154 (Special Issue on Accessing Information in Spoken Audio). (PDF ) G. Tur, D. Hakkani-Tur, A. Stolcke, & E. Shriberg (2001), Integrating Prosodic and Lexical Cues for Automatic Topic Segmentation, Computational Linguistics, 27(1), 31-57. (PDF) E. Shriberg & A. Stolcke (2001), Prosody Modeling for Automatic Speech Understanding: An Overview of Recent Research at SRI. In M. Bacchiani, J. Hirschberg, D. Litman, & M. Ostendorf (eds.), Proc. ISCA Tutorial and Research Workshop on Prosody in Speech Recognition and Understanding, pp. 13-16, Red Bank, NJ. (PDF) E. Shriberg, A. Stolcke, & D. Baron (2001), Can Prosody Aid the Automatic Processing of Multi-Party Meetings? Evidence from Predicting Punctuation, Disfluencies, and Overlapping Speech. In M. Bacchiani, J. Hirschberg, D. Litman, & M. Ostendorf (eds.), Proc. ISCA Tutorial and Research Workshop on Prosody in Speech Recognition and Understanding, pp. 139-146, Red Bank, NJ. (PDF) A. Stolcke & E. Shriberg (2001), Markovian Combination of Language and Prosodic Models for better Speech Understanding and Recognition . Invited talk at the IEEE Workshop on Speech Recognition and Understanding, Madonna di Campiglio, Italy, December 2001. (PDF) D. Baron, E. Shriberg, and A. Stolcke (2002), Automatic Punctuation and Disfluency Detection in Multi-Party Meetings Using Prosodic and Lexical Cues. Proc. Intl. Conf. on Spoken Language Processing, Denver, vol. 2, pp. 949-952. (PDF) |
||||
{kind=link}
About Us
 R&D Divisions
Careers
Newsroom
Contact Us
R&D Divisions
Careers
Newsroom
Contact Us
©2011 SRI International, 333 Ravenswood Avenue, Menlo Park, CA 94025-3493
SRI International is an independent, nonprofit corporation. Privacy policy
Last modified Aug 23, 2022