
The Speakers in the Wild (SITW) Speaker Recognition Challenge SRI is hosted the Speakers in the Wild (SITW) speaker recognition challenge for Interspeech 2016 using a newly collected database. The SITW database contains hand annotated speech samples from open source media for the purpose of benchmarking speaker recognition technology on single and multi-speaker audio acquired across unconstrained or 'wild' conditions. The SITW speaker recognition challenge will serve as the release of this corpus to the public for research purposes. The conditions represented in the SITW database provide samples of nearly 300 individuals across clean interview, red carpet interviews, stadium conditions, outdoor conditions, and multi-speaker scenarios. Each individual also has speech acquired using camcorders or cellphones and void of professional editing. Several hundred individuals are represented across a range of challenging conditions in the SITW database in which speaker identities have been visually confirmed through video. All noise, reverb, compression and other artifacts in the corpus are natural characteristics of the original audio. Applying speaker recognition technology to recognizing the same speaker across such varying conditions is expected to be difficult, as we believe these conditions represent some of the major challenges still faced by current technology and its application to real-world data. The aim of the SITW challenge was to encourage teams across the world to benchmark current technologies and develop novel algorithms for the task of speaker recognition under the conditions in the SITW database. The database now publicly available free of charge for research to any interested organization. In addition to handling single-speaker and multi-speaker test audio, an optional condition of semi-supervised enrollment will be explored. In this condition, systems are given a single or multi-speaker audio file along with a small annotation of where the speaker of interest is speaking in the file. The system is then tasked with finding additional speech from the speaker before enrolling the speaker model. The 2016 Evaluation Leaderboard We are pleased to present the results of the SITW Speaker Recognition Challenge evaluation track in which we received 45 submissions from 11 teams around the world! The team leaderboard below contains the best submission from each team per condition ranked by the primary metric Cdet. 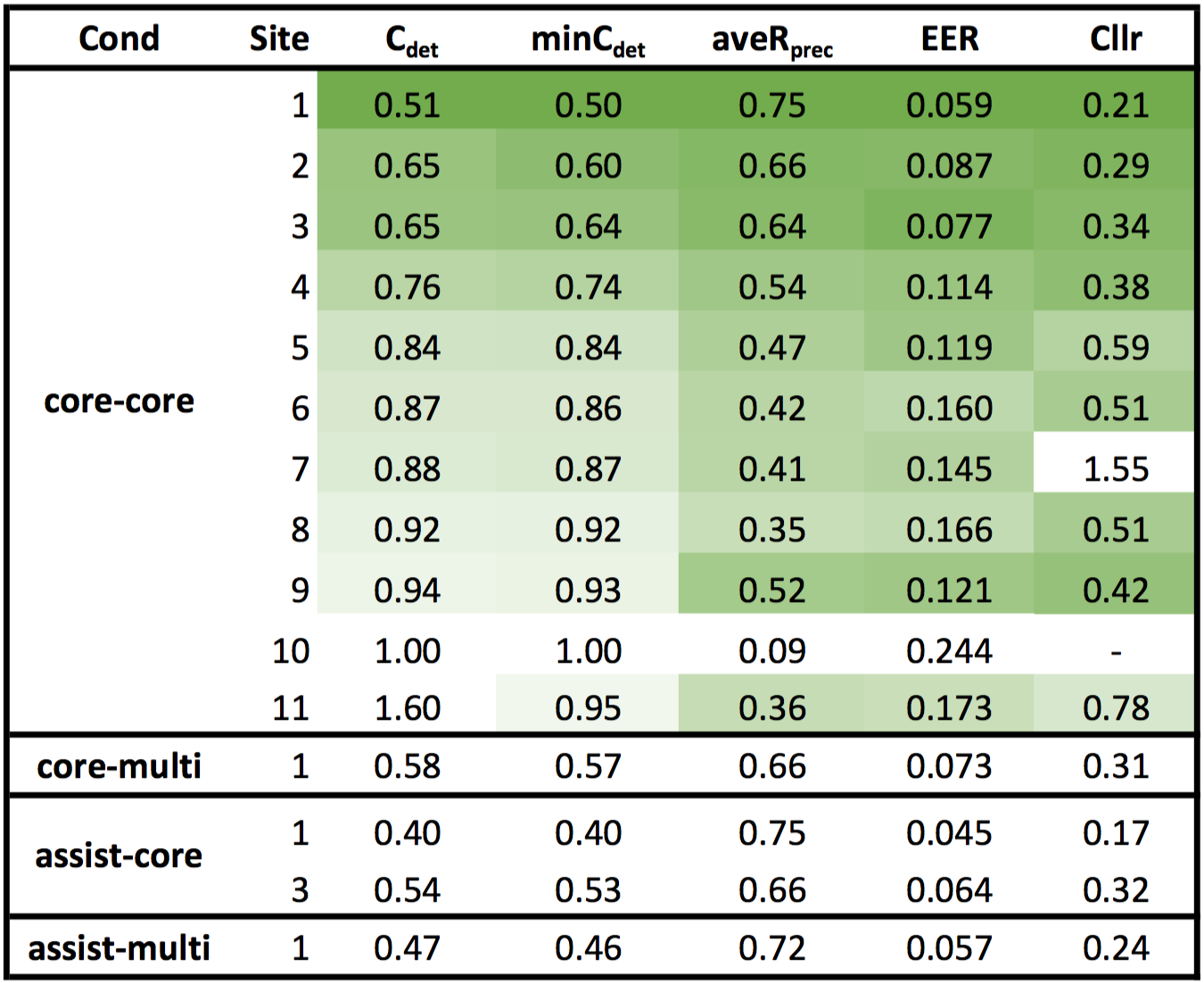
Obtaining the SITW database The SITW challenge was hosted for the purpose of special session publications at Interspeech 2016. The SITW database has been publicly released to the research community free of charge and restricted to research purposes. The release coincided with Interspeech 2016 when all research from the challenge was also published such that the research community could benefit from the experiments and analysis from many international research groups on the SITW database. Please contact the organizers at sitw_poc@speech.sri.com if you would like to obtain the database and have your email added to the SITW database email list in order to receive future news and updates on the database. Contact Please email data requests and questions regarding the SITW challenge to sitw_poc@speech.sri.com News
|
||||
About Us
 R&D Divisions
Careers
Newsroom
Contact Us
R&D Divisions
Careers
Newsroom
Contact Us
©2011 SRI International, 333 Ravenswood Avenue, Menlo Park, CA 94025-3493
SRI International is an independent, nonprofit corporation. Privacy policy
Last modified Sep 08, 2016